在当今数字化时代,人工智能(AI)已成为推动技术进步和创新的关键力量。苹果公司,作为全球科技领域的巨头之一,一直在不断探索和创新,以提供更加智能和个性化的用户体验。2024年的WWDC大会上,苹果公司揭开了其最新力作——Apple Intelligence的神秘面纱,这是一款全新的个人智能化系统,旨在彻底改变用户与设备之间的互动方式。

Apple Intelligence是什么
Apple Intelligence是苹果公司开发的一款集成在 iPhone、iPad 和 Mac 平台上的个人智能系统,于北京时间2024年6月11日的WWDC大会(苹果全球开发者大会)上发布。该AI系统通过结合强大的生成模型和个人背景,为用户提供有用且相关的服务和体验。Apple Intelligence 的核心在于其先进的 AI 技术和隐私的重视,不仅能够理解用户的需求,还能预测用户的意图,在保护用户隐私的同时还能提供更加个性化的服务。
Apple Intelligence的核心功能
AI驱动的写作工具
写作工具是 Apple Intelligence 的一项系统级功能,能够帮助用户在各种应用程序中重写、校对和总结文本。无论是撰写电子邮件、润色博客文章还是整理课堂笔记,这些工具都能让用户在写作时更加自信。用户可以调整文本的语调、检查语法错误,甚至获得文本内容的简洁摘要。
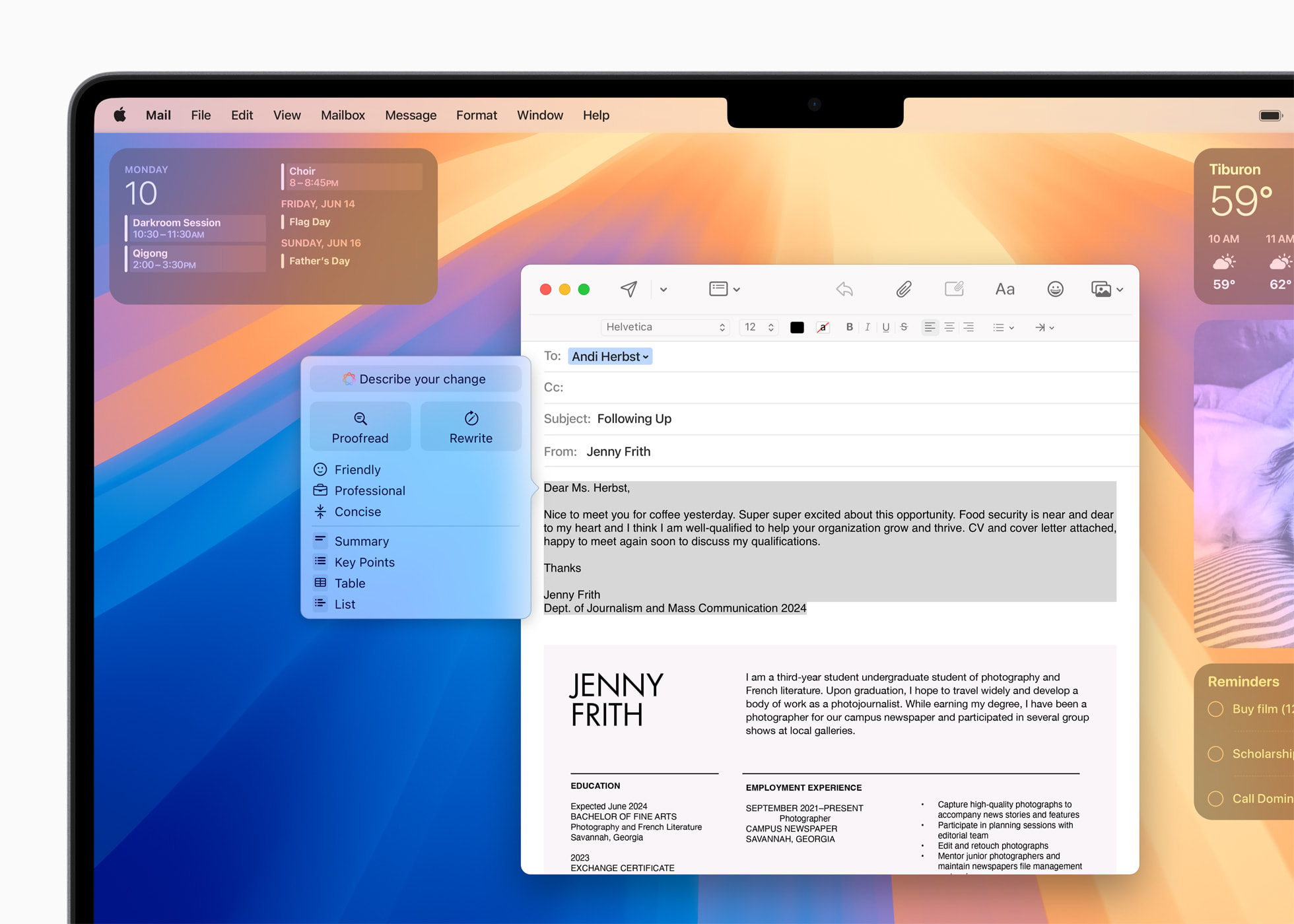
Genmoji和Image Playground
Apple Intelligence 还为用户的图像和表情符号带来了乐趣和创造力。通过新的Image Playground,用户可以生成三种风格的有趣图像:动画、插图或草图。用户可以创建自定义的表情符号,即“Genmoji”,完美捕捉瞬间和独特的表达方式。此外,使用图像魔杖(Image Wand),用户还可以将草图转换成精致的图像。
改进的照片和视频体验
照片应用也得到了增强,新增了自然语言搜索功能,用户可以轻松找到视频中的特定时刻。新的清理工具可以去除背景中的干扰物,而不会改变主题。通过“记忆”功能,用户只需简单描述即可创建自定义的故事。

隐私和安全
Apple Intelligence 在 AI 领域设定了新的隐私标准。首先,它拥有在设备上完全运行的小模型,以本地处理请求。当更复杂的任务需要云处理时,它们有一个新的私有云计算功能,同时确保用户的数据不会被保留或暴露。

Siri的全面升级
Siri 通过 Apple Intelligence 得到了全面的升级。现在,Siri 更好地理解用户,能够跟随用户的思路,保持请求之间的上下文,甚至允许用户通过打字代替说话。Siri 还可以在应用程序中执行数百种新操作,例如从朋友那里获取书籍推荐或检查父母的航班状态。

ChatGPT集成
苹果公司还在其平台上整合了OpenAI旗下的ChatGPT。Siri 可以在用户允许的情况下,利用 ChatGPT 的专业知识来回答问题。ChatGPT 将在系统级的写作工具中提供帮助,生成内容和图像。ChatGPT 用户还可以连接他们的账户以访问付费服务。
Apple Intelligence的技术细节
Apple Intelligence 建立在苹果公司创建的一系列生成模型之上,包括设备上的和服务器基础模型、图像生成的扩散模型和编码模型。此外,Apple Intelligence 还可以根据需要调用第三方模型,如 ChatGPT,以处理更复杂的请求。

设备端的模型
设备上的模型拥有约 30 亿参数和 49K 的词汇量,采用低比特量化和分组查询注意力技术,以提高速度和效率。在 iPhone 15 Pro 上,该模型实现了每个提示token 0.6 毫秒的时间到生成第一个token的延迟和每秒 30 个token的生成速率。
服务器端的模型
服务器端的模型拥有 100K 的词汇量,能够使用私有云计算处理更复杂的任务,同时确保隐私和安全。该模型使用高级技术,如推测性解码和上下文修剪,以提高性能。建立在强化的 iOS 基础子集上,通过强大的加密和安全的启动过程确保用户数据的隐私。
训练和优化
苹果的模型是在精心策划的数据集上训练的,这些数据集不包含任何个人用户数据。训练数据包括授权数据、由 AppleBot 收集的公开可用数据和合成数据。训练后,苹果使用诸如拒绝采样微调和基于人类反馈的强化学习等新颖算法,以提高模型遵循指令的能力。
苹果实施了一系列尖端技术,以确保在移动设备上的最优性能和效率。通过使用分组查询注意力、共享嵌入表、低位palletization和高效的键值缓存更新等方法,苹果成功创建了高度压缩的模型,这些模型在满足移动设备的内存、功率和性能限制的同时,保持了质量。

低秩适应(LoRA)
与 Google 的 Gemini Nano 和 Microsoft 的 Phi 等通用模型不同,苹果的模型通过使用一种称为“低秩适应”的技术,对日常活动进行了微调,如摘要、邮件回复和校对。这种技术涉及将小型神经网络模块插入预训练模型的各个层中。这允许模型适应不同任务,同时保留其通用知识。重要的是,这些适配器可以动态加载和交换,允许基础模型针对手头的任务进行专门处理。
如何使用Apple Intelligence
Apple Intelligence面向用户免费提供,测试版将于今年秋季作为 iOS 18、iPadOS 18 和 macOS Sequoia 的内置功能推出,仅支持英语(美国)。部分功能、软件平台和其他语言支持将于明年陆续推出。Apple Intelligence 将仅支持 iPhone 15 Pro、iPhone 15 Pro Max 以及搭载 M1 或后续芯片的 iPad 和 Mac 设备,需将 Siri 和设备的语言设置为英语(美国)。
常见问题
Apple Intelligence 基于苹果公司开发的一系列生成模型,包括设备上的3B小型模型和服务器上的更复杂模型,以及必要时调用的第三方模型如ChatGPT。
Apple Intelligence计划在秋季推出Beta版本,最初将只在美国英语中提供,暂不在国区提供服务,后续可能扩展到中国市场。
Apple Intelligence使用在设备上运行的小模型来本地处理请求,并在需要云处理时使用Private Cloud Compute,确保数据不被保留或暴露。
Siri现在能更好地理解用户,保持请求间的上下文,允许打字代替说话,并能执行跨应用的数百种新操作。
延伸阅读















